Databricks Cost Exports with nOps Platform
Video Tutorial
How the Integration Works
The Databricks integration with Inform follows a streamlined process to collect and analyze your billing data:
-
Integration Setup
- Identify the S3 bucket in your AWS account
- Deploy the CloudFormation stack provided by nOps to grant
GetObjectandListBucketpermissions to the bucket and the required prefix
noteMake sure to be logged into the correct AWS account to proceed with this step.
-
Data Upload from Databricks
- nOps provides a Python script that extracts billing data from your Databricks workspace
- Schedule this script as a job in your Databricks environment to periodically upload the billing data to the configured S3 bucket
-
Data Retrieval by nOps
- nOps fetches the billing files from the specified bucket and prefix using the granted permissions
-
Data Processing
- The retrieved data is processed and displayed within the Inform product, providing actionable insights into your Databricks usage
To integrate Databricks with Inform, follow these steps:
- Enter S3 Bucket Details
- Deploy CloudFormation Stack
- Schedule Databricks Job
Accessing Inform Integrations
To begin, navigate to the Organization Settings and click on Integrations. From there, select Inform to proceed with setting up your Databricks integration.
Below is an example of the integrations page:

This page provides access to configure and manage integrations with your Inform tools.
The list of integrations will indicate whether there are any active integrations or if the tools are not yet integrated. Active integrations will be marked accordingly, allowing you to easily identify the current status of each integration.
Step 1: Enter S3 Bucket Details

To configure the S3 bucket for nOps file uploads, follow these steps:
-
Select the Correct AWS Account
- From the dropdown, select the AWS account where the S3 bucket resides.
-
Enter Bucket Details
- Bucket Name: Enter the name of your existing S3 bucket or create a new one.
- Prefix: Specify a unique prefix (e.g.,
nops/) to ensure nOps only accesses files meant for the integration.
importantIf you already have an S3 bucket configured for Databricks to write files, it's recommended to use that bucket to avoid additional setup steps on Databricks.
- If you don't have an S3 bucket configured this way, follow these setup instructions to create the bucket and set it up in Databricks.
-
Save the Configuration
- Once the account, bucket name, and prefix are entered, click Setup to store these details.
-
Redirect to CloudFormation Setup
- After clicking Setup, you will be automatically redirected to create a CloudFormation stack for granting necessary permissions.
importantMake sure to be logged in the account selected to proceed with the following step.
Step 2: Deploy CloudFormation Stack
- On the redirected page, the parameters should be prefilled.
- Click on the checkbox to acknowledge the creation of IAM resources and click Create stack

- Click on the checkbox to acknowledge the creation of IAM resources and click Create stack
Ensure the stack is deployed successfully. This step is crucial for nOps to access your data.
Step 3: Schedule Databricks Job
After the steps above, you should see something like this in your Databricks integration
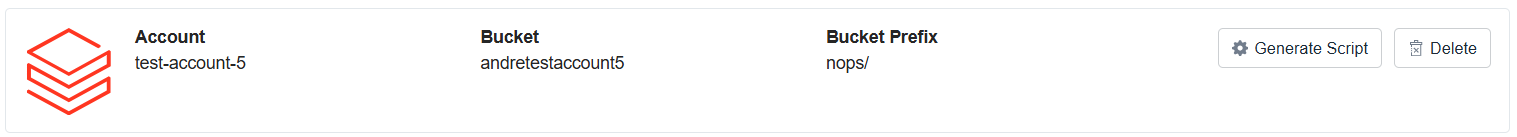
- Generate Script:
- Click the Generate Script button to obtain the billing extraction script.
- Use the Copy button (shown below) to copy the script to your clipboard for use in Databricks.

Ensure you copy the entire script accurately, as it contains the necessary configurations for Databricks to upload billing data to the S3 bucket.
-
Create a Notebook:
- Log in to your Databricks workspace.
- Navigate to the Workspace section.
- Click the Create button and select Notebook.
- Name your notebook (e.g.,
NopsDatabricksBillingDataUploader) and choose the appropriate language (Python). - Copy and paste the script into the notebook.
-
Schedule the Job Directly from the Notebook:
-
Click on Schedule in the top-right corner of the notebook toolbar.
-
In the Add Schedule dialog:

- Set the frequency to Every 1 day.
- Select the appropriate compute (cluster) for the job.
- Click More options
- Add +Add
- Enter role_arn on key and enter the role_arn in the value field
- Add +Add

-
Click Create to finalize the schedule.
-